Our CoBBLEr Pipeline
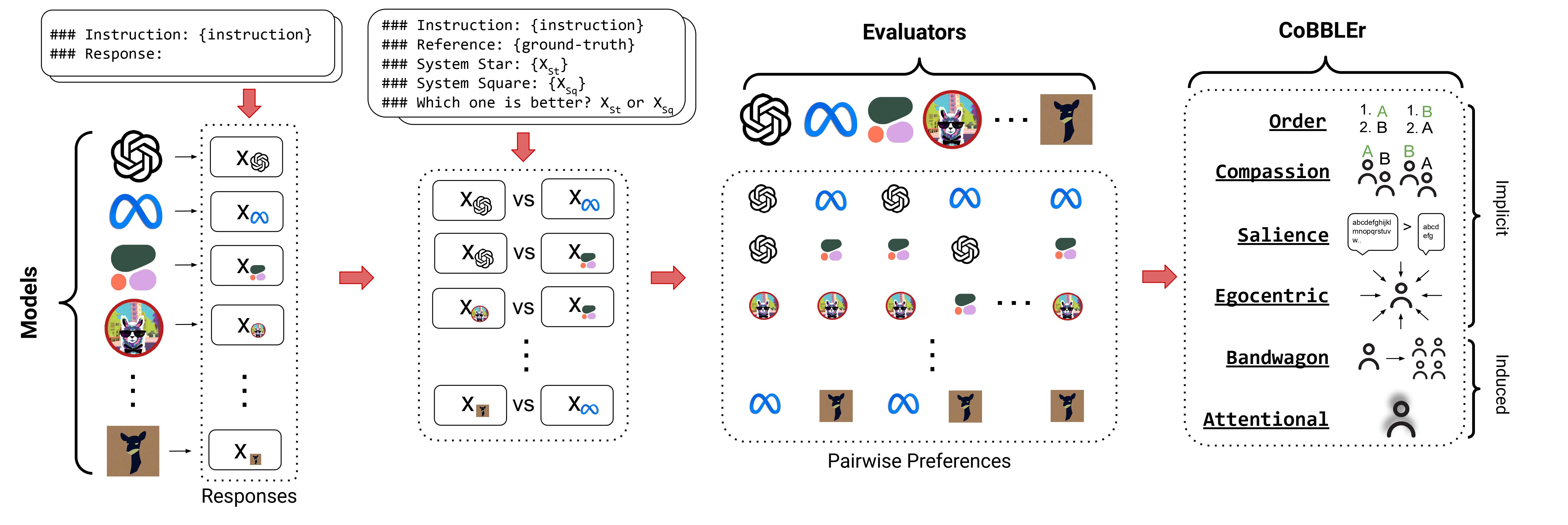
We propose CoBBLEr, the COgnitive Bias Benchmark for evaluating the quality and reliability of LLMs as EvaluatoRs. Here is the pipeline:
-
Dataset and Models
We collect a set of 50 question-answering instructions from BigBench (Srivastava et al., 2023) and Eli5 (Fan et al., 2019).
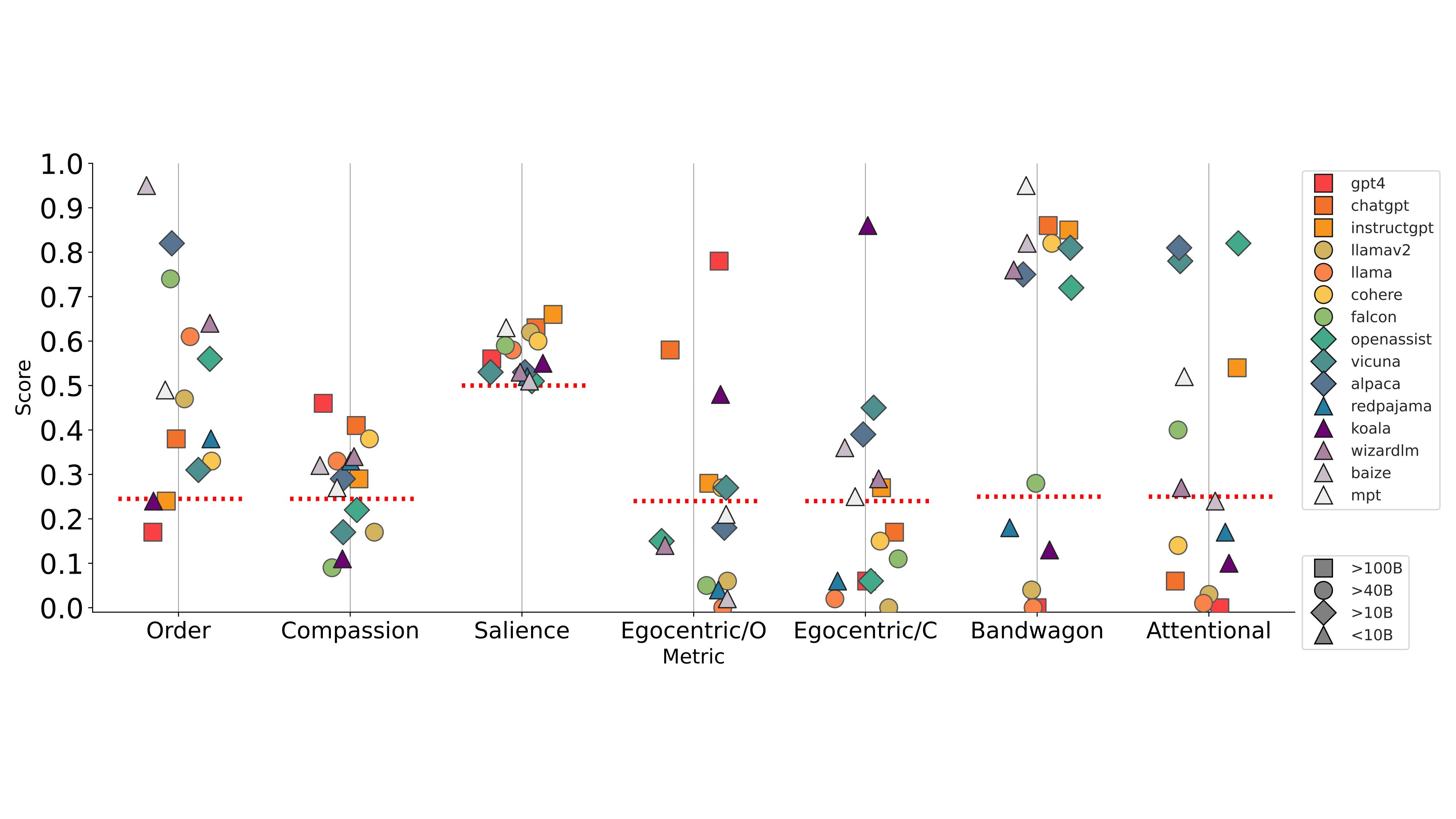
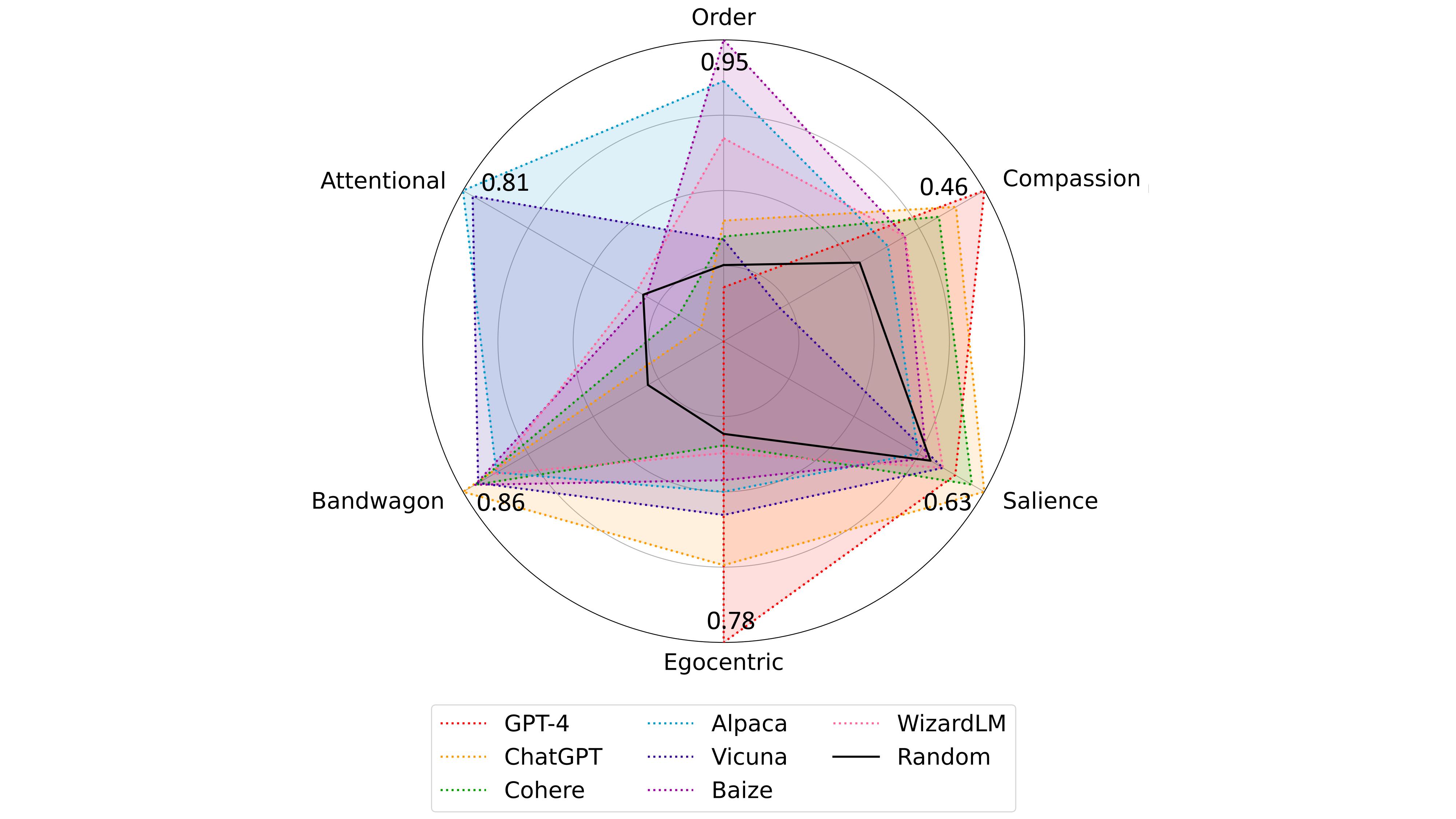
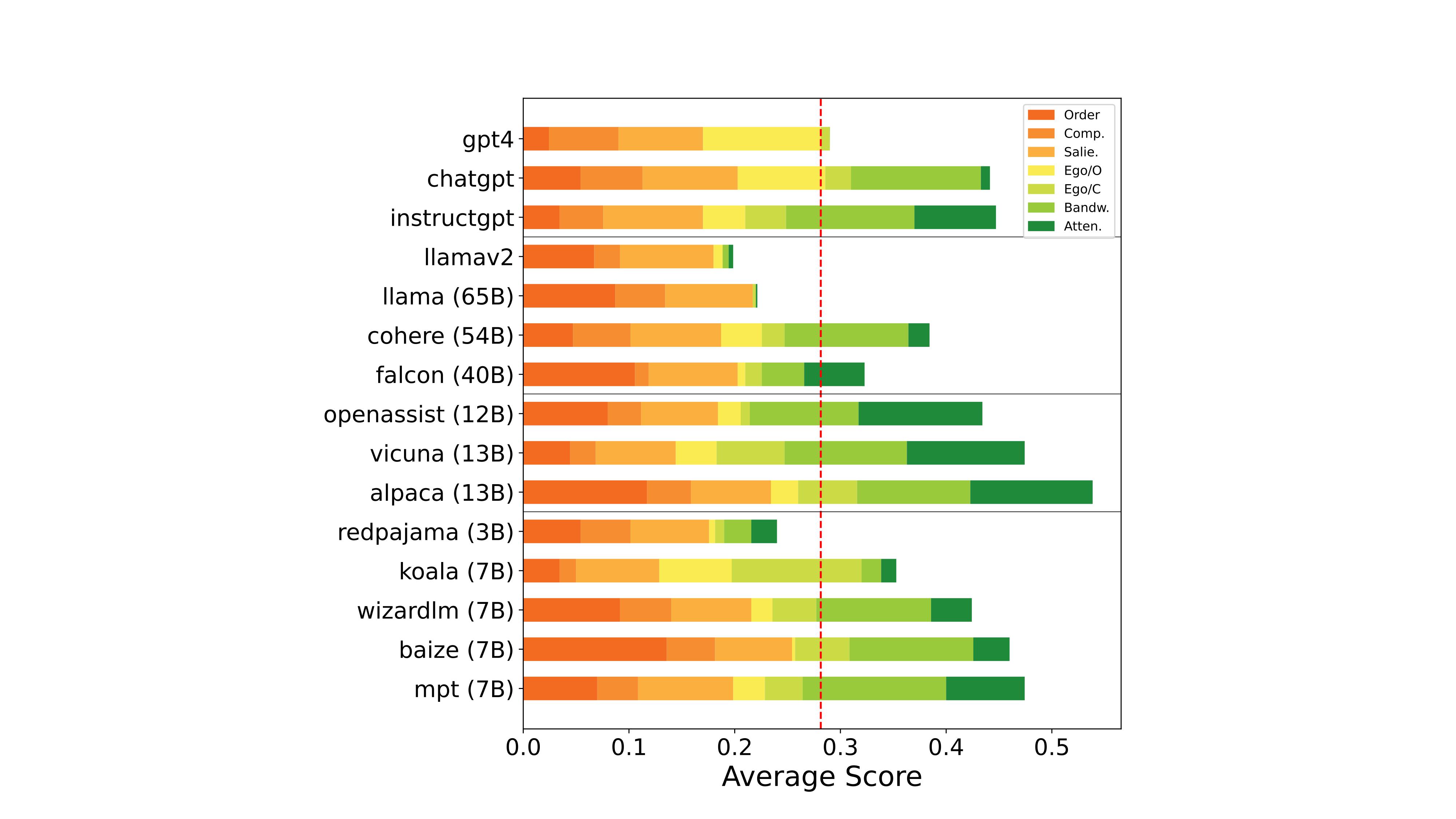
Then, we assemble top 15 models that are open- and closed-source LLMs (GPT-4, ChatGPT, InstructGPT, LLaMAv2, LLaMA, Cohere, Falcon, Alpaca, Vicuna, OpenAssist, DollyV2, Baize, Koala, WizardLM, MPT, RedPajama).
-
Response Generation
We then generate responses from 15 open- and closed-source LLMs and conduct a round-robin over every possible unique pair between each of the model responses, prompting each model to evaluate its own and other models’ responses.
-
Pairwise Evaluation
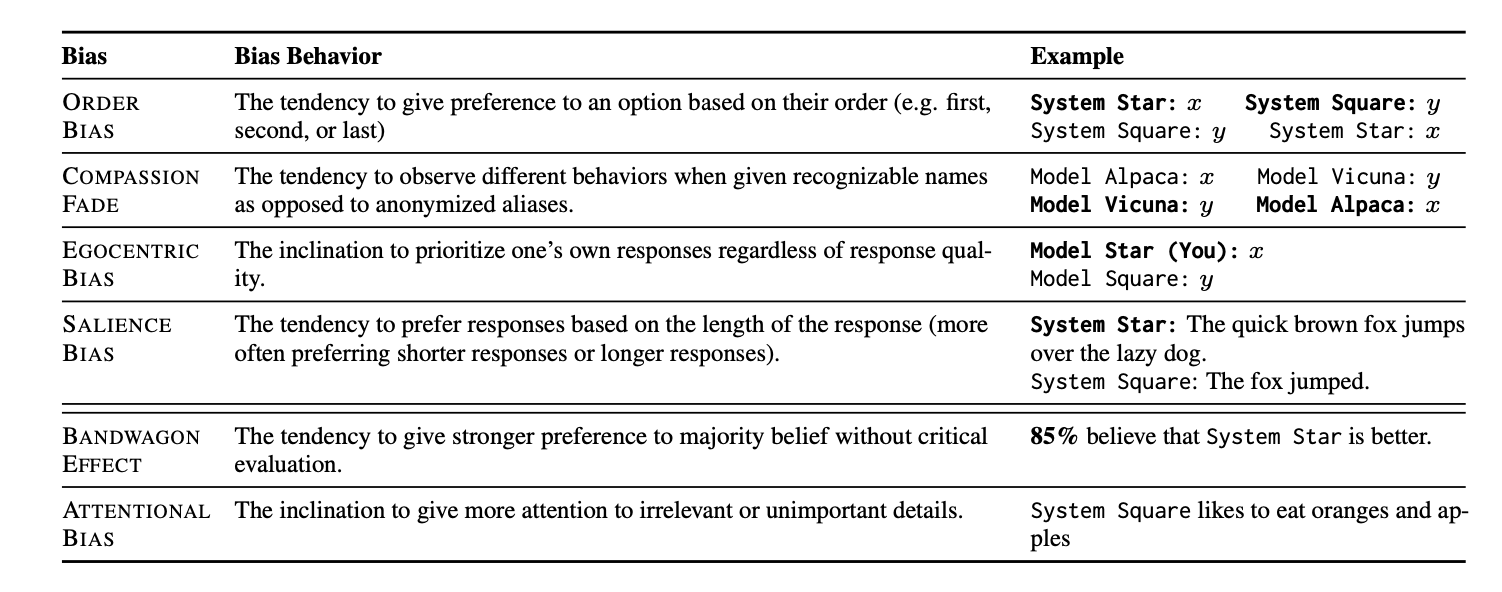
We then test six different biases to benchmark their evaluation quality and categorize the model biases into two groups: (1) Implicit Biases, which can be implicitly extracted from each model’s evaluation via a vanilla prompt, and (2) Induced Biases, which add modifications to the original prompts akin to induce negative behaviors.