, University of Minnesota
, University of Minnesota
We are recruiting for ScholaWrite 2.0,
We're studying how researchers work — from first idea to finished paper
ScholaWrite: A Dataset of End-to-End Scholarly Writing Process
🎉 ACL 2026
🎉 ACL 2026
Scholarly writing is a cognitively demanding, non-linear, and multi-intentional process that involves frequent switching between planning, drafting, and revising — contrasting fundamentally with the token-by-token text generation of large language models (LLMs). We introduce ScholaWrite, the first dataset capturing the end-to-end scholarly writing process: nearly 62K LaTeX-based keystroke edits collected from 5 computer science preprints over 4 months, authored by 10 researchers and annotated with 15 fine-grained writing intention categories. We make three contributions:
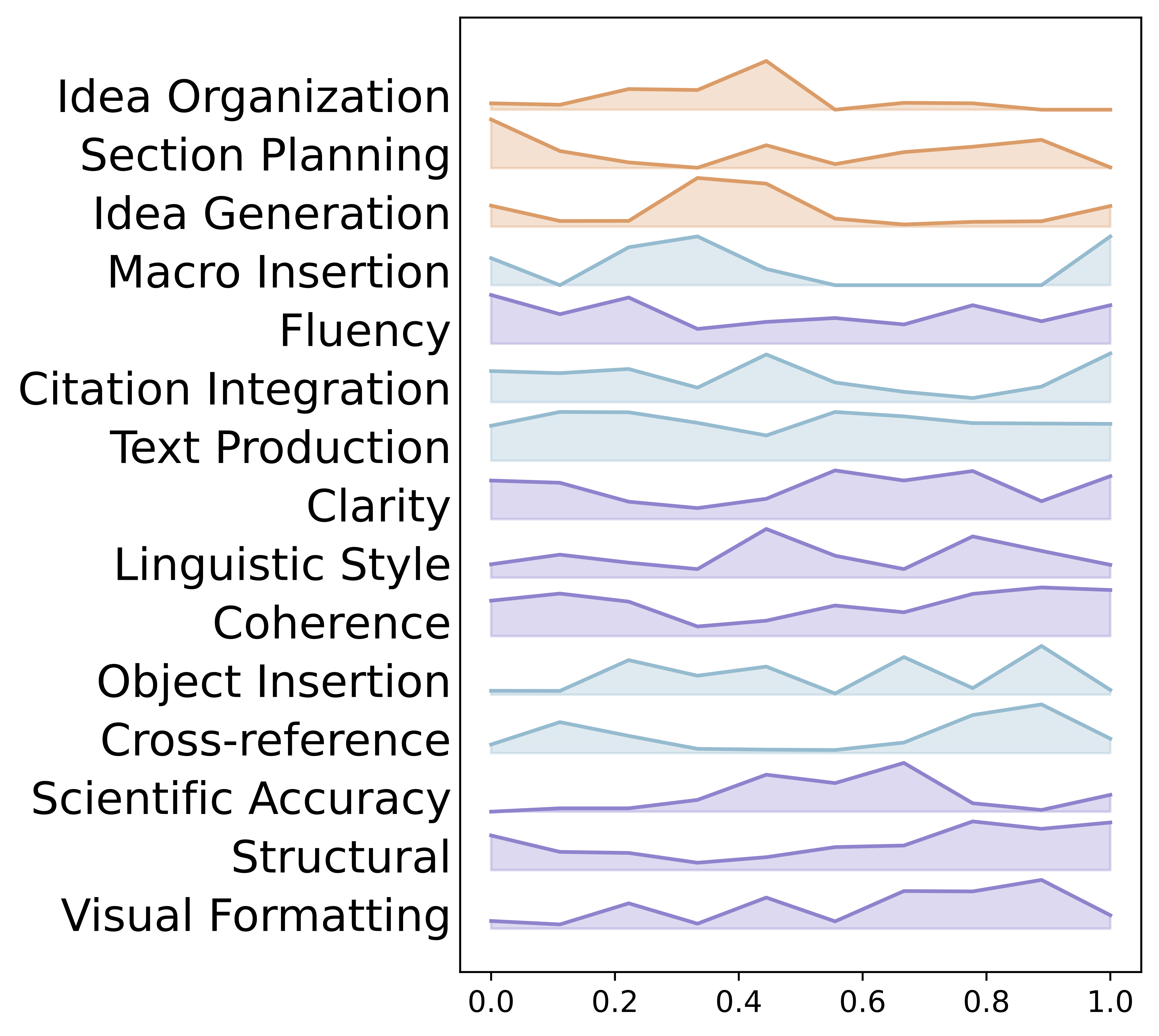
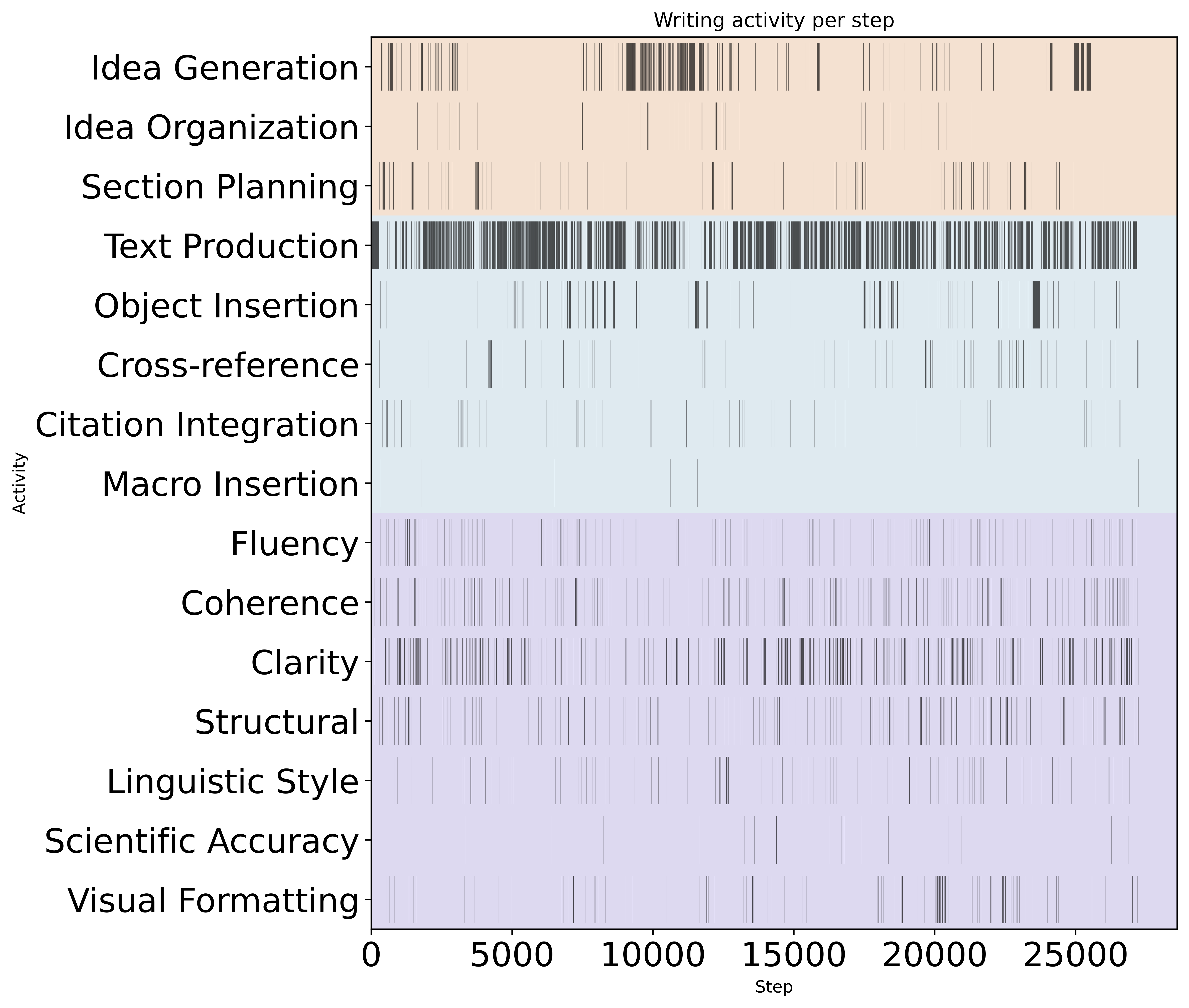
Finding 1: Writing is Non-Linear and Multi-Intentional
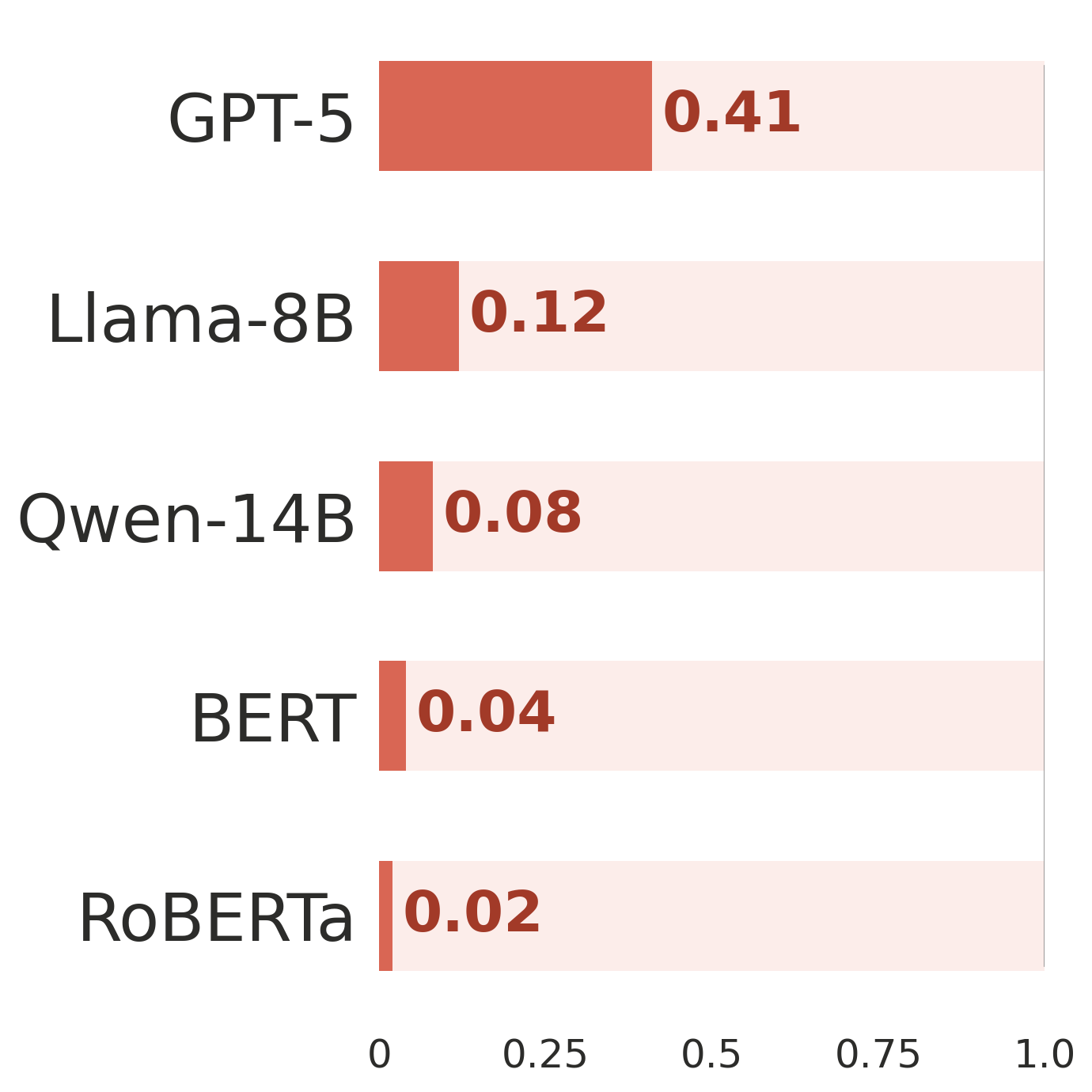
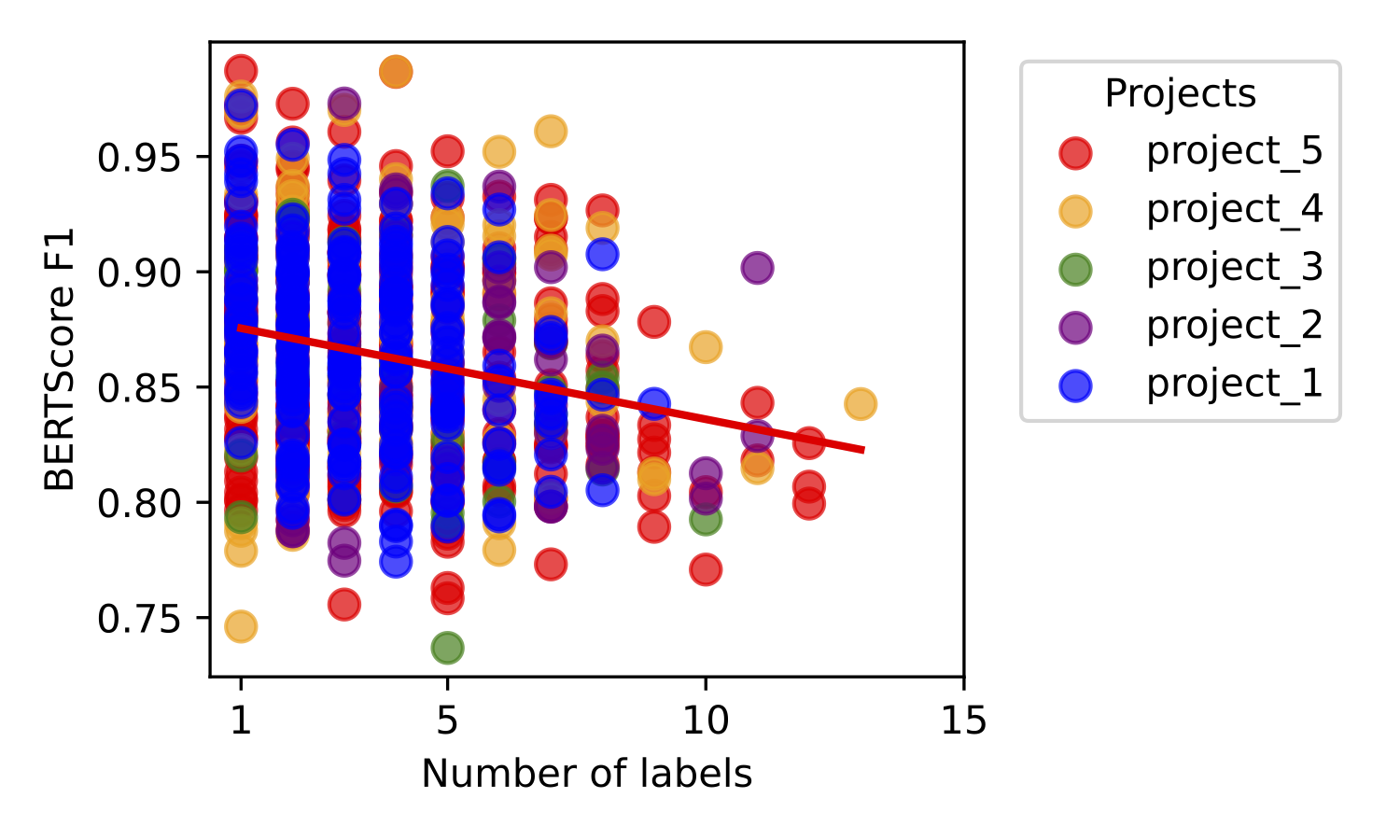
Contrary to how LLMs generate text, scholarly writing is not a linear progression. Writers constantly shift between planning, drafting, and revising, often within a single session.

Below is a data entry of one keystroke data in scholawrite. You can find the full dataset in the Huggingface data card
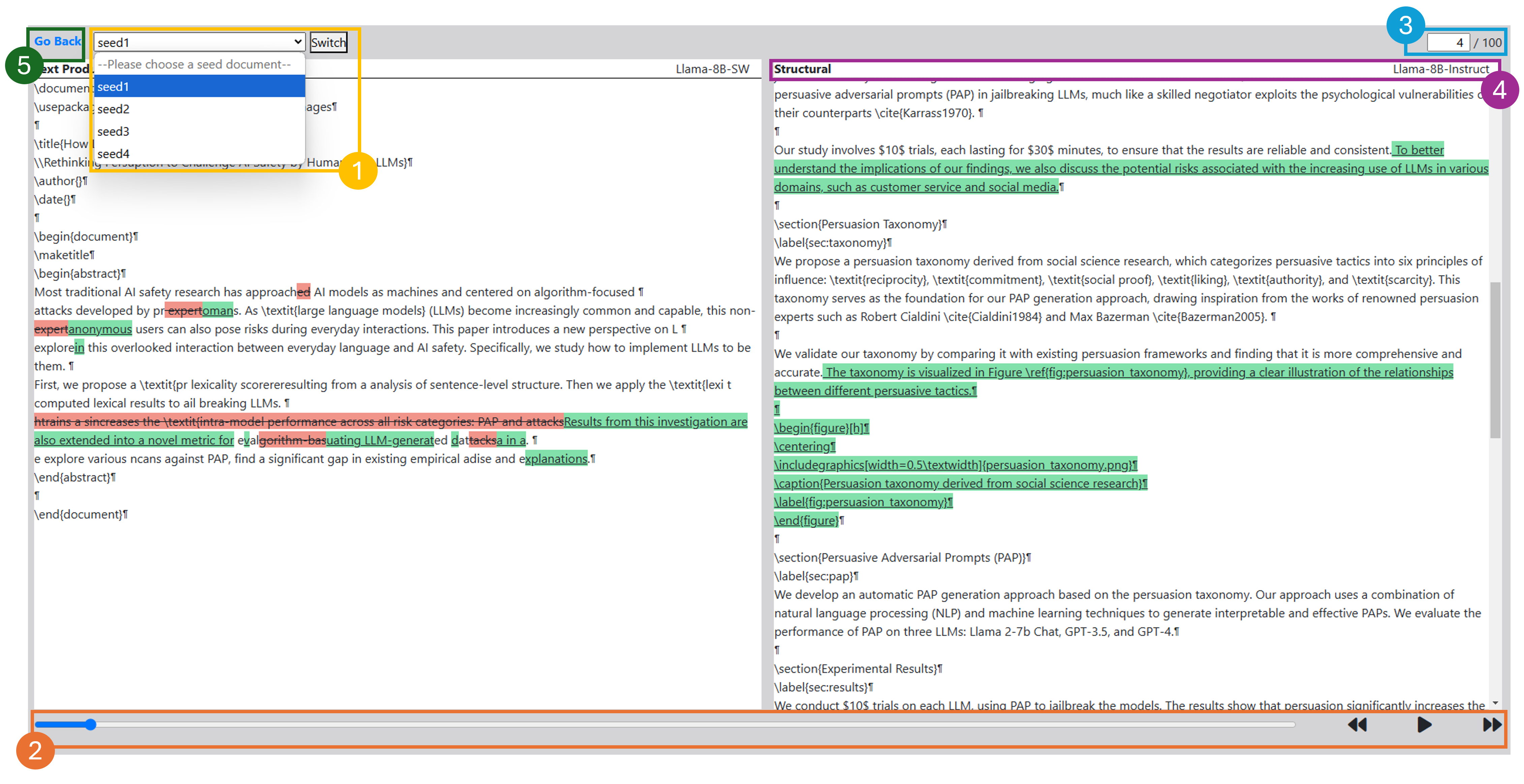
We fine-tuned Llama-3.1-8B-Instruct on ScholaWrite for two tasks: predicting the next writing intention, and generating text edits aligned with that intention. Given a seed document (a LaTeX-formatted abstract from an award-winning NLP paper), the model predicts what a human writer would do next, applies the edit, and repeats — producing a full writing trajectory over 100 iterations. Here is how it unfolds:























ScholaWrite 2.0 is launching! Here's what we aim to do:
Capture the complete research journey — from first idea to finished paper — across multiple academic fields and researchers at different career stages.
Uncover patterns in how researchers search, read, write, and collaborate, including how they use AI tools throughout the process.
Develop an AI assistant that understands researchers' real workflows and can provide support without disrupting their thinking process.
Participants install a lightweight app that records work sessions and connects to everyday tools (Google Docs, Slack, GitHub, etc.). If you'd like to contribute your research activities to this dataset or want to join us in building ScholaWrite 2.0, please fill out this form and we'll reach out shortly!
Our lab has several ongoing projects collecting research workflows — see the full list at minnesotanlp.github.io/ai4sci-data.
@inproceedings{le-etal-2026-scholawrite,
title = "{S}chola{W}rite: A Dataset of End-to-End Scholarly Writing",
author = "Le, Khanh Chi and
Wang, Linghe and
Lee, Minhwa and
Volkov, Ross and
Chau, Luan Tuyen and
Kang, Dongyeop",
editor = "Liakata, Maria and
Moreira, Viviane P. and
Zhang, Jiajun and
Jurgens, David",
booktitle = "Proceedings of the 64th Annual Meeting of the {A}ssociation for {C}omputational {L}inguistics (Volume 1: Long Papers)",
month = jul,
year = "2026",
address = "San Diego, California, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2026.acl-long.1606/",
doi = "10.18653/v1/2026.acl-long.1606",
pages = "34755--34788",
ISBN = "979-8-89176-390-6",
abstract = "Writing is a cognitively demanding activity that requires constant decision-making, heavy reliance on working memory, and frequent shifts between tasks of different goals. To build writing assistants that truly align with writers' cognition, it is necessary to capture and analyze the complete thought process behind how writers transform ideas into final texts. We present SCHOLAWRITE, the first dataset of end-to-end scholarly writing, tracing the multi-month journey from initial drafts to final manuscripts. The dataset traces nearly 62K LaTeX-based edits from five computer science preprints over four months and is enriched with fine-grained annotations of cognitive writing intentions. We demonstrate the value of ScholaWrite through three complementary contributions: (1) analysis of real-world writing behavior reveals that scholarly writing is highly non-linear and multi-intentional, blending rapid drafting bursts with cognitively sustained writing sessions; (2) evaluations of current large language models show that they struggle to provide meaningful support throughout the human writing process; and (3) models finetuned on SCHOLAWRITE demonstrate improved alignment with human writing workflows. SCHOLAWRITE underscores the value of capturing scientists' cognitive writing process and provides actionable insights and resources for the development of future writing assistants."
}